Latitude - Prompt Engineering Platform
My Role
Product Designer
Team
- Gerard Clos CTO
- Andres Gutierrez Senior Software Engineer
- Carlos Sansón Software Engineer
- César Migueláñez CEO
Timeline
Aug - Oct, 2024
Overview
Latitude LLM is an AI prompt engineering platform to create and deploy prompts with confidence. It allows collaboration, saving different versions, gaining observability into prompt performance, and refining to achieve maximum success for companies building AI-based products.
Context
When creating a new collaborative BI platform at Latitude, we started working on a chatbot with AI to answer users' questions. During the process of creating the chatbot, we realized that creating a good prompt is not easy.
Other companies were suffering from this problem too, and that's how we pivoted to create an all-in-one platform to develop prompts and AI-based products.
Problem
At Latitude, we encountered the problem of creating good prompts for a data chatbot. Then, we started researching and talking with other companies, and we found out that this problem was common. The main problems are:
- LLMs are not deterministic – They are powerful, but sometimes they are not accurate or have hallucinations.
- Susceptible to changes – Any change in the prompt can impact the output's performance, improving specific cases but degrading others.
- Collaboration is hard - Some companies put the prompt in the code, and domain experts or other non-technical members can't edit it.
- Lack of observability - It's hard to know a prompt's performance in production and test it with real data before deploying it.
- No control over iterations - Each company has its own system to track prompt versions and their performance; however, these systems are unreliable. For instance, some companies manually add data to an Excel spreadsheet, making it difficult to compare versions and iterate safely.
Opportunity
After the research, we found many companies suffering from common problems with new technology, like LLMs, which are growing rapidly week by week. It's projected that by 2030 the global LLM market will be $259 billion.
The market is young and was lacking a solution to this problem, so we could build a product to fill the gap and take advantage of the wave. This way we pivoted to position Latitude as the go-to platform for prompt engineering.
Solution
After analyzing the problem, we started thinking about the solution. We divided it into 3 parts: Build, Evaluate, and Refine.
First, we had to cover the basics: build and test the prompt easily. Then, evaluate it and have observability about the performance. Finally, the extra step to provide real value: help users refine the prompt and close the loop, increasing accuracy and success.
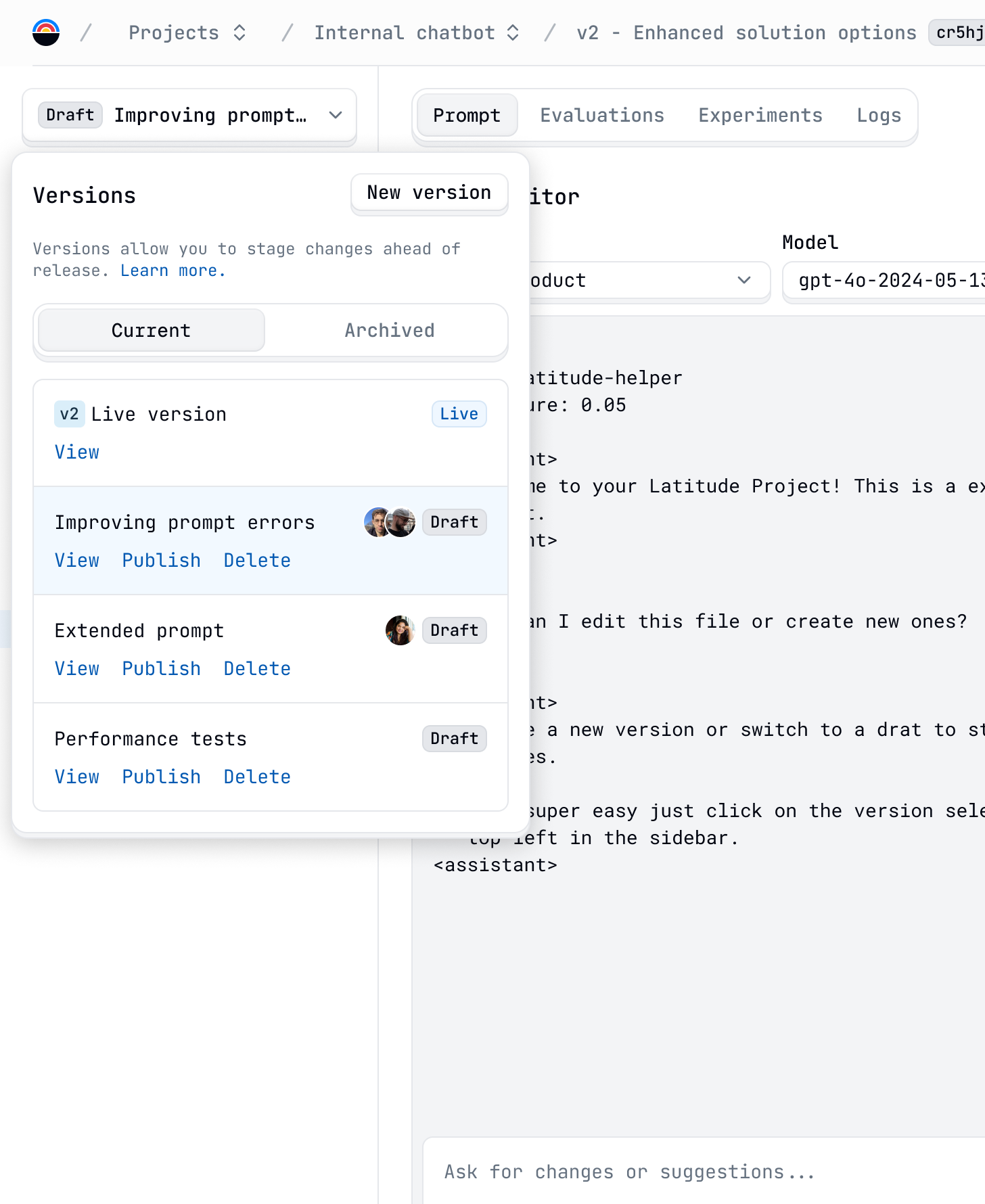
Projects and Version Control
First step was solving the problem of collaboration and tracking prompt iterations. We based Latitude on projects and a version control system similar to Git.
Each project can contain multiple prompts, which are essentially files with instructions for the LLM. These prompts also have versions, which store the history of the prompts and their modifications.
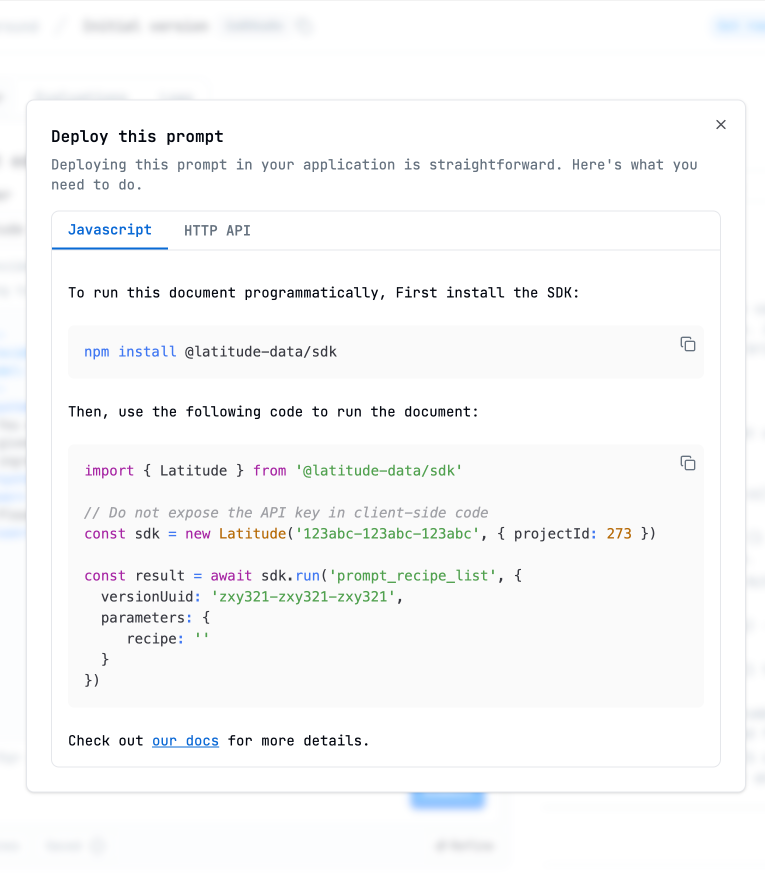
Here, both developers and other team members can be aligned, working together in a draft version, editing a prompt before deploying it. Once deployed, the version is live, and users can access the prompts in their apps through our API or SDK.
Editor
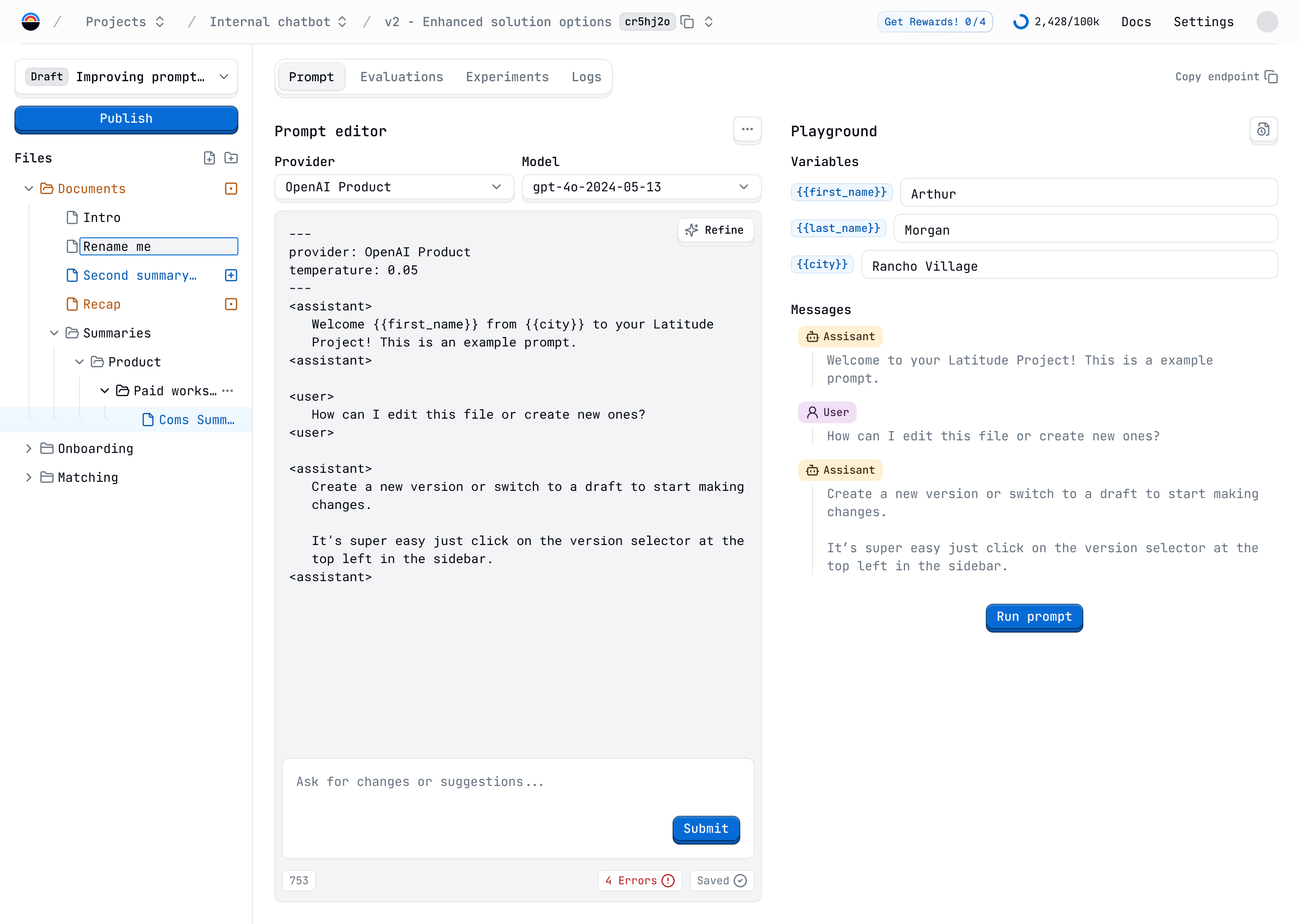
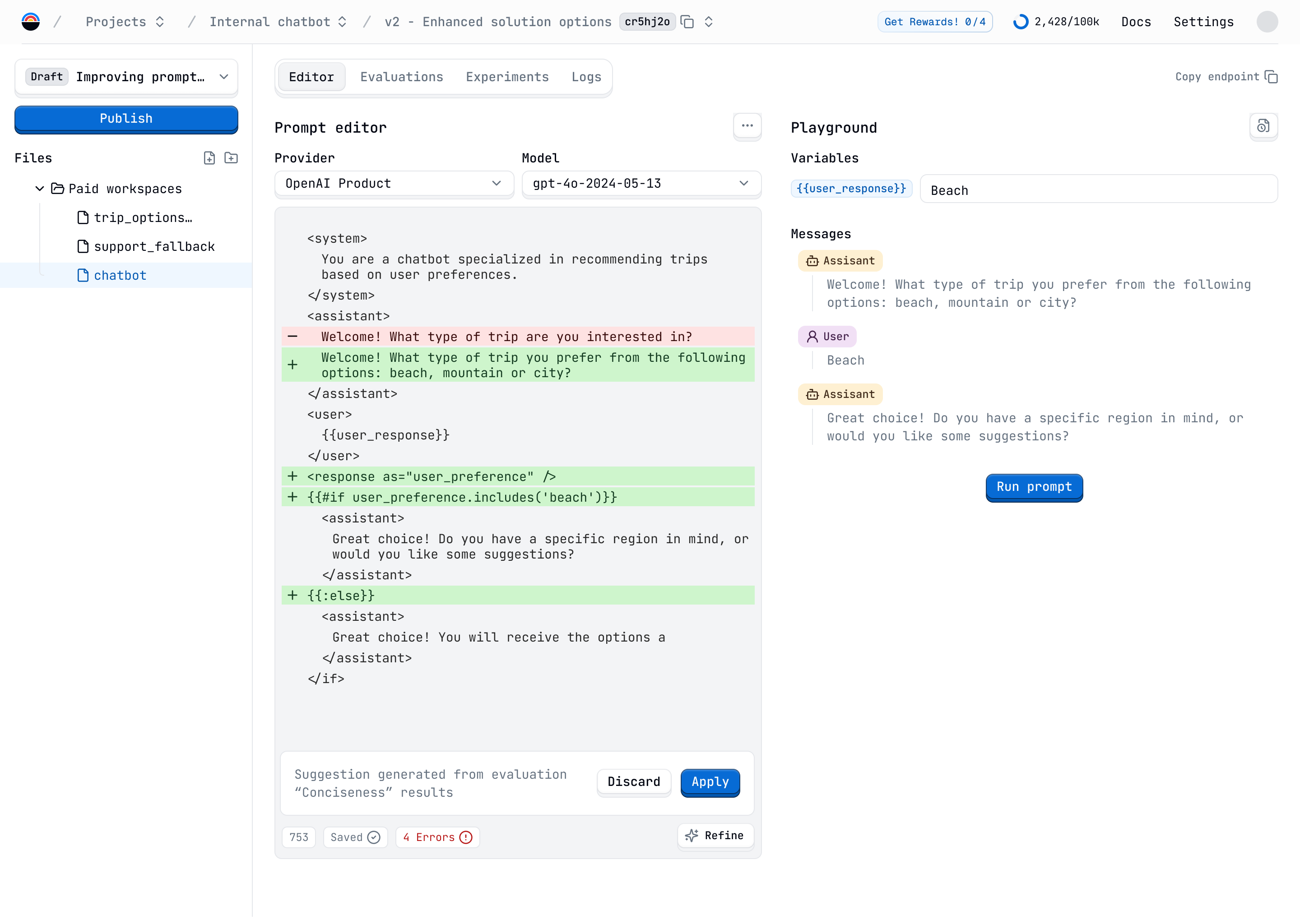
The second step was to create an editor to build and edit the prompts. Here, users have available a simple tag syntax to define the system, user, and assistant messages.
Also, we added logic to cover most complex prompt patterns. The user can reference other prompts, use parameters, loops, conditions, and chains of prompts to reuse the results of one prompt in another.
A live preview of the prompt was important so that the user can see the result of the prompt and test it in real time while editing it.
Evaluations
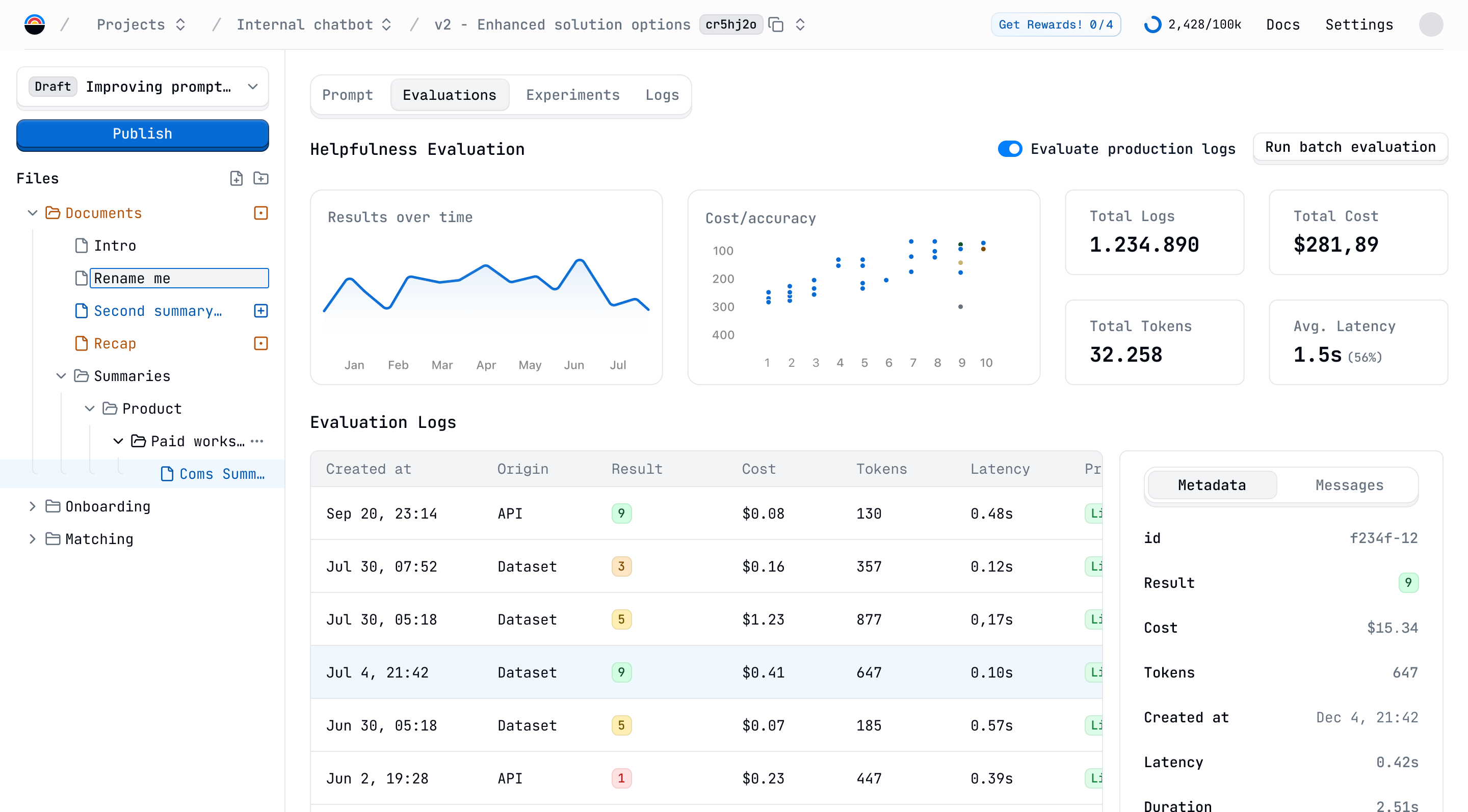
The part to build and collaborate on the prompts is covered, but users still have the problem of uncertainty about the performance of the prompt.
We solve this problem with evaluations. Basically, evaluations are other prompts with instructions to analyze the output of a prompt and return a score. This way, they can ensure the quality of the prompt before and after deploying it using test data and production logs.
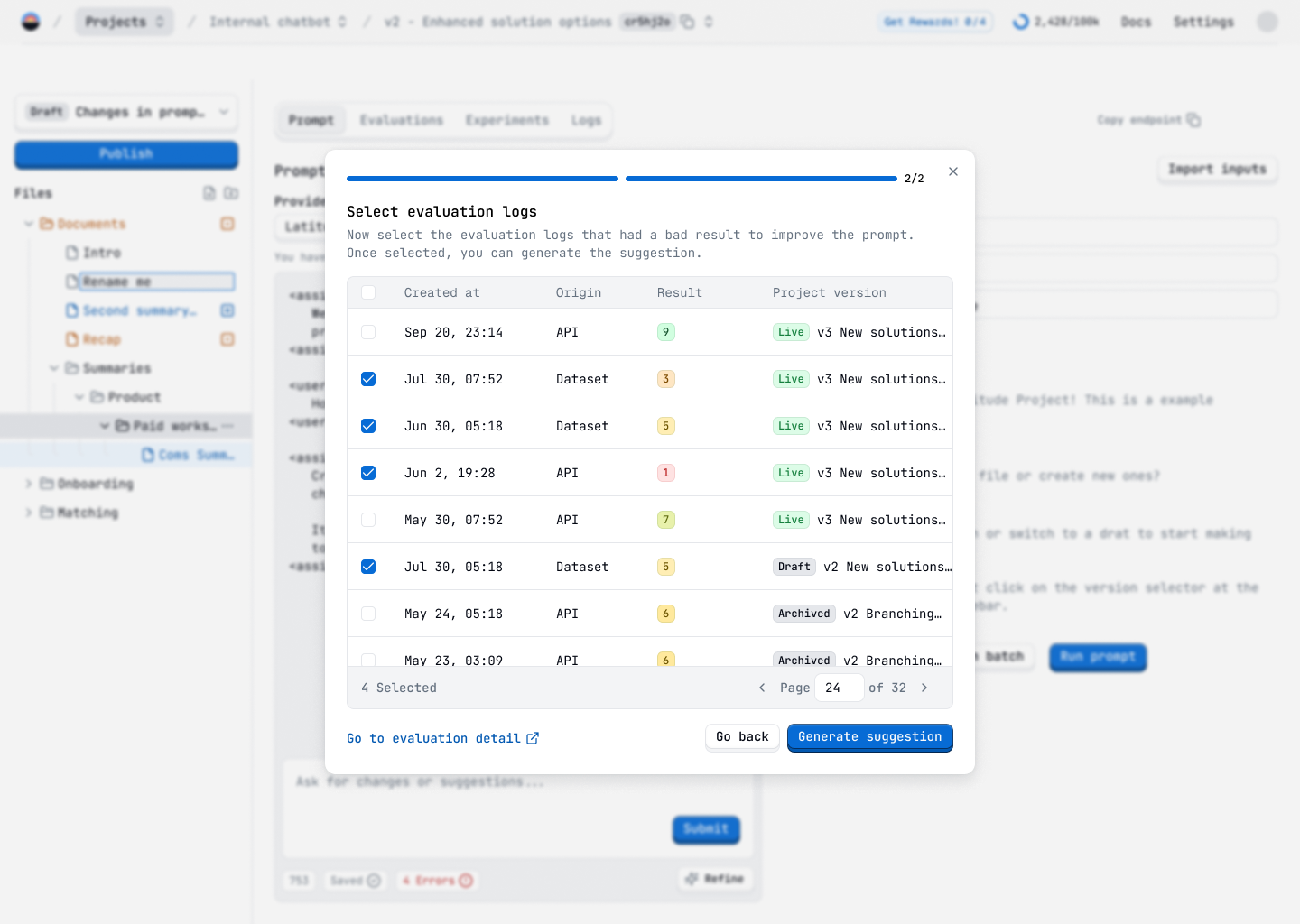
Refiner and Copilot
The final step is to turn the evaluation results into action and close the loop. Now that the user knows the prompt isn't working, how can it be improved?
We added a feature to allow the user to refine the prompt using the evaluation results. Basically, they can pass bad evaluation results to our refiner system, which is a series of prompts to improve the original prompt. This way, instead of starting from scratch, the user can use the results of the evaluation to improve the prompt and test it again with no effort.
In this way, we also added a more open way to improve the prompt using the Copilot system; this system is an LLM-based assistant that already knows the syntax and capabilities of the platform, so it can help the user with any request about the prompt.
Success
To validate the solution, we have been talking to potential users. The process has been divided into three steps: 1. a first interview to understand the problem and the context, 2. a second interview with a prototype of the solution to get feedback and iterate, 3. and third, opening a beta to let users test the solution and receive real feedback and track usage metrics.
During the first month, we have more than 1,000 users registered, and a retention rate between 10% and 20%. The next step is to iterate on the product and increase this metric.